

| << Chapter < Page | Chapter >> Page > |
Hierdie hoofstuk gee jou die geleentheid om te bou op wat jy in die vorige grade geleer het oor data hantering en waarskynlikheid. Die werk sal meestal prakties van aard wees. Deur probleemoplossing en aktiwiteite, sal jy die tegnieke van saamstel, organiseer, vertoon en analisering van data bemeester. Jy sal ook leer hoe om data te interpreteer en om die data krities te kan beoordeel en nie op sigwaarde te beoordeel nie. Dit is belangrik, aangesien data somtyds wangebruik en misbruik word om verkeerdelik standpunte te bewys of ondersteun. Mates van sentrale geneigdheid (gemiddeld, mediaan en modus) en dispersie (strekking, persentiel, kwartiel, inter-kwartiel, semi-inter-kwartiel strekking, variansie en standaard afwyking) sal ondersoek word. Natuurlik sal die meeste van julle bekend wees met die waarskynlikheidsaktiwiteite – julle het byvoorbeeld al dobbelsteenspeletjies en kaartspeletjies gespeel. Jou basiese verstaan van waarskynlikheid en kans sal verdiep word om ook te verstaan hoe dit gebruik kan word.
Die mate van sentrale geneigdheid (gemiddeld, mediaan en modus) en mate van dispersie (kwartiele, persentiele, strekking) verskaf inligting van die data waardes by die middel van die datastel en verskaf inligting oor die verspreiding van die data. Die inligting van die verspreiding is egter gebaseer op data waardes by spesifieke punte in die datastel. Byvoorbeeld die eindpunte is die strekking en die datapunte wat die stel in vier ewe groot groepe opdeel gee die kwartiele. Die gedrag van die hele datastel word dus nie hiervoor beoordeel nie.
Een metode wat ‘n aanduiding te gee van die verspreiding in ‘n datastel is is om te bereken wat die verskil is tussen die datapunte en die gemiddeld. Die twee belangrike maatstawwe wat gebruik word, is die variansie en die standaard afwyking van die data stel.
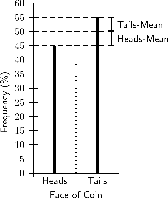
Die variansie van ‘n datastel is die gemiddeld van die kwadraat van die verskil tussen elke datapunt en die gemiddeld. ‘n voorbeeld van wat hierdie beteken word gewys in [link] . Die grafiek verteenwoordig die resultaat van 100 keer se skiet van ‘n muntstuk, wat op 45 kop en 55 stert uitslae uitgeloop het. Die gemiddeld van die resultaat is 50 (helfte van 100). Die kwadraat van die verskil tussen die kop waardes en die gemiddeld is en die kwadraat van die verskil tussen die stert waardes en die gemiddeld is . Die gemiddeld van hierdie twee kwadratiese verskille gee die variansie .
Laat die populasie bestaan uit elemente , met gemiddeld (lees as "x streep"). Die variansie van die populasie, aangedui met , is die gemiddeld van die kwadraat van die verskil tussen elke datapunt en die gemiddeld.
Aangesien die populasie variansie kwadreer word, is dit nie direk vergelykbaar met die gemiddeld nie, en ook nie met die datapunte nie.
Laat die steekproef bestaan uit die elemente , geneem van ‘n populasie, met gemiddeld . Die variansie van die steekproef, aangedui met , is die gemiddeld van die kwadraat van die afwykings van die steekproef gemiddeld:
Notification Switch
Would you like to follow the 'Siyavula textbooks: wiskunde (graad 11)' conversation and receive update notifications?

|
|
|
|

|
|

|
|

|
|

|
|
|
|
|
|
|
|
|
|
|