

| << Chapter < Page | Chapter >> Page > |
A = -B + C * D / E
Tomando todo como una unidad, la sentencia tiene cuatro operadores y cuatro operandos:
/ ,
* ,
+ y
- (negación), y
B ,
C ,
D , y
E . Claramente es demasiado para que quepa en una cuádrupla. Necesitamos una forma con exactamente un operador y, cuando mucho, dos operandos por sentencia. La versión que sigue lo lleva a cabo, empleando variables temporales para almacenar los resultados intermedios:
T1 = D / E
T2 = C * T1T3 = -B
A = T3 + T2
Por supuesto, un lenguaje intermedio utilizable requiere de algunas otras características, como apuntadores. Estamos por sugerir la creación de nuestro propio lenguaje intermedio para investigar cómo trabajan las optimizaciones. Para comenzar, necesitamos establecer unas pocas reglas:
X := Y op Z , que significa
X optiene el resultado de
op aplicado a
Y y
Z .t
n .Si estamos construyendo un compilador, deberemos ser un poco más específicos. Para nuestros propósitos con esto basta. Considere el siguiente fragmento de código en C:
while (j<n) {
k = k + j * 2;m = j * 2;
j++;}
Este ciclo se traduce en la representación en lenguaje intermedio que se muestra a continuación:
A:: t1 := j
t2 := nt3 := t1<t2
jmp (B) t3jmp (C) TRUEB:: t4 := k
t5 := jt6 := t5 * 2
t7 := t4 + t6k := t7
t8 := jt9 := t8 * 2
m := t9t10 := j
t11 := t10 + 1j := t11
jmp (A) TRUEC::
Cada línea de código fuente en C se representa mediante varias sentencias en LI. En muchos procesadores RISC, nuestro código LI es tan parecido al lenguaje máquina que podemos traducirlo directamente a código objeto.
Véase
[link] para algunos ejemplos de código máquina obtenido directamente a partir de lenguaje intermedio. A menudo el nivel más bajo de optimización consiste en una traducción literal del lenguaje intermedio a código máquina. Cuando esto sucede, el código generalmente es muy largo y su rendimiento es pobre. Al revisarlo, puede usted encontrar lugares donde ahorrar unas pocas instrucciones. Por ejemplo,
j se carga en variables temporales en cuatro lugares; seguramente podemos reducirlo. Tenemos que realizar algo de análisis y algunas optimizaciones.
Tras generar nuestro lenguaje intermedio, queremos cortarlo en bloques básicos . Se trata de secuencias de código que comienzan con una instrucción que o bien sigue una bifurcación o es en sí misma el destino de un salto. Dicho de otra forma, cada bloque básico tiene una entrada (en la parte superior) y una salida (en la parte inferior). [link] representa nuestro código LI como un grupo de tres bloques básicos. Estos bloques hacen el código más fácil de analizar. Al restringir el flujo de control al interior de un bloque básico de arriba hacia abajo y eliminar todas las bifurcaciones, podemos asegurarnos que si se ejecuta la primera sentencia, también lo hará la segunda, y así sucesivamente. Por supuesto, las bifurcaciones no han desaparecido, pero las hemos forzado afuera de los bloques en la forma de flechas de conexión - el grafo de flujo .
Lenguaje intermedio dividido en bloques básicos
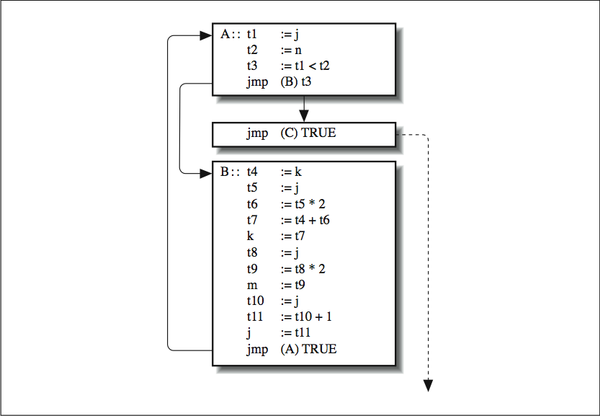
Ahora somos libres de extraer información de los bloques mismos. Por ejemplo, podemos decir con certeza cuáles variables usa cierto bloque, y cuáles define (les asigna valor), cosa que no hubiéramos podido ser capaces de hacer si el bloque contuviera una bifurcación. También podemos reunir la misma clase de información sobre los cálculos que realizan. Tras haber analizado los bloques, de forma tal que sepamos qué entra y qué sale de ellos, podemos modificarlos para mejorar el rendimiento, sin preocuparnos acerca de la interacción entre bloques.
Notification Switch
Would you like to follow the 'Cómputo de alto rendimiento' conversation and receive update notifications?

|
|
|
|

|
|

|
|

|
|

|
|

|
|
|
|
|
|
|
|

|