

| << Chapter < Page | Chapter >> Page > |
Foute kan insluip by enige data-opnames. Onwillekeurige foute kom voor in alle datastelle en staan soms bekend as nie-sistematiese foute. Onwillekeurige foute kan ontstaan as gevolg van die skatting van datawaardes, onakkuraatheid van instrumente, ens. As jy byvoorbeeld lengtes aflees van 'n liniaal, kan onwillekeurige foute insluip in elke meting as gevolg van die skatting tussen watter twee lyntjies die lengte lê. Wanvoorstellings (vals voorstellings) staan ook soms bekend as sistematiese foute. Wanvoorstellings in 'n datastel kom voor wanneer die datawaardes deurlopend oor- of onderskat word. Wanvoorstellings kan ook ontstaan wanneer korreksiefaktore nie in aanmerking geneem word nie of wanneer instrumente nie behoorlik gekalibreer is nie (kalibrering is die proses waarin instrumente gemerk word volgens vooraf gedefinieërde mate). Wanvoorstellings lei tot die berekening van 'n foutiewe steekproefgemiddelde wat groter of kleiner kan wees as die ware gemiddelde.
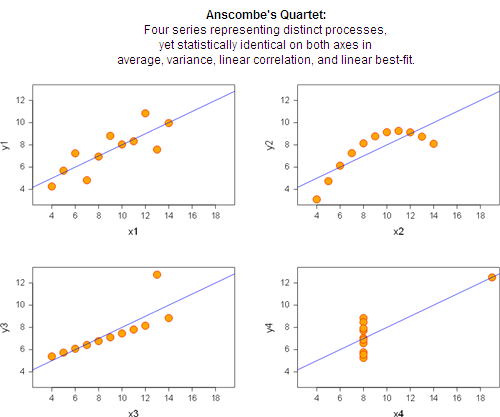
Baie mense aanvaar statistieke goedsmoeds en pas dit blindweg toe of haal dit aan. Dit is egter nie wys nie want die data wat aanleiding gee tot die statistieke moet noukeurig oorweeg word. 'n Welbekende voorbeeld van verskeie datastelle wat lei na dieselfde statistiese analise (die proses waarin data ondersoek word en maatstawe van sentrale neiging bereken word, ens.) terwyl hulle in der waarheid baie van mekaar verskil, is Anscombe se kwartet. Dit word getoon in
[link] .
In Graad 11 sal jy metodes bestudeer wat gebruik word om data grafies voor te stel. Op die oomblik egter, hoef jy slegs te verstaan dat ons datawaardes op die Cartesiese vlak kan voorstel op soortgelyke wyse as waarmee ons grafieke geteken het. As elk van die datastelle in Anscombe se kwartet statisties geanaliseer word, vind ons dat die gemiddelde, variansie, korrelasie en lyne van beste passing (hierdie terme sal in latere grade verduidelik word) identies is. Wanneer ons egter die data, in plaas van om dit statisties te analiseer, eenvoudig stip, kan ons sien dat die datastelle baie van mekaar verskil. Hierdie voorbeeld wys vir ons dat dit baie belangrik is om sowel die onderliggende datastel as die statistiese afleidings in aanmerking te neem. Ons kan nie aanneem dat omdat ons oor die statistieke van 'n datastel beskik, ons noodwendig weet wat die datastel ons vertel nie. Ter wille van interessantheid, word sommige van die wyses waarop statistieke en data verkeerd geïnterpreteer en wanvoorgestel word, in die volgende uitbreiding van die afdeling gegee.
In baie omstandigheide kan groepe voordeel trek daaruit om mense te mislei met die misbruik of wanvoorstelling van statistieke.
Algemene tegnieke wat gebruik word sluit in:
Notification Switch
Would you like to follow the 'Siyavula textbooks: wiskunde (graad 10) [caps]' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|
|
|
|
|
|

|
|

|