We seek to understand Palm's definition of cell assembly in context. In particular, we seek to determine whether a brain-sized random graph can contain a realistic number of assemblies by Palm's definition.
In this report, we describe the process of k-assembly enumeration and explain some preliminary experimentation using that algorithm.
The report exists in two forms. The abridged version includes the material described above, while the full version goes on to include more trend examples, an extensive collection of visual examples of k-Assemblies, and implementation.
This is the abridged version. The full version is available
here .
Finding k-assemblies
Finding k-assemblies takes place in two steps: k-core enumeration and k-assembly confirmation:
K-core enumeration
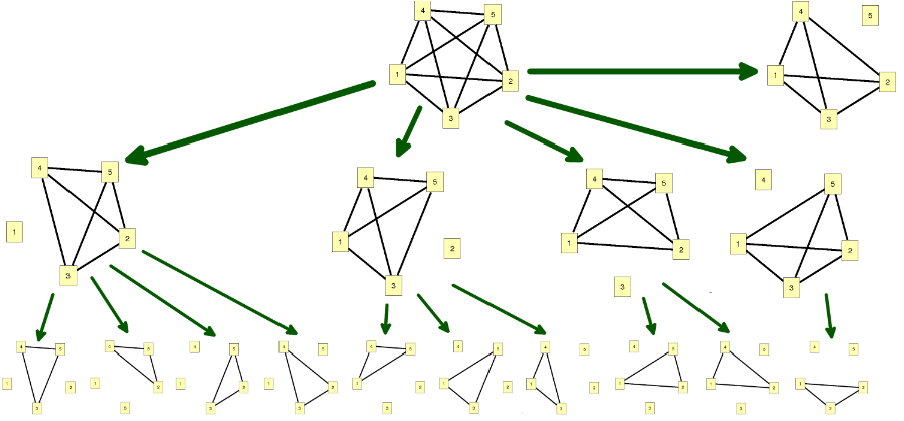
The process of k-Core enumeration follows the general form of a branch and bound algorithm. That is, it follows the process:
If possible, solve the problem, otherwise:
Break the problem into several smaller problems, for each of these smaller problems, go to step 1.
Applied to our problem, the general algorithm looks like this, given some input graph
(
[link] ):
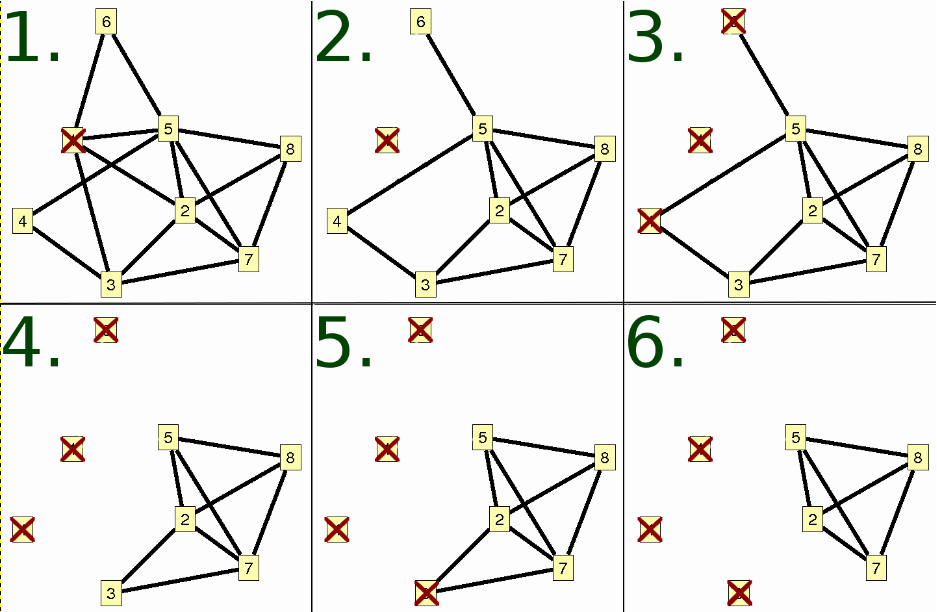
An exhaustive 2-core enumeration: Ultimately, every induced subgraph is enumerated except those that are not 2-cores.The maximum k-core algorithm for a 3-core: 1,2) A vertex is eliminated from the graph, leaving an induced subgraph which is not a minimal 3-core. 3,4) All vertices which have insufficient degree with respect to the new subgraph graph (less than 3 in this case) are eliminated. 5,6) Again, a vertex without sufficient degree is eliminated. The subgraph pictured in step 6 has no vertices of less than k degree, so the process is completed.
If
is a minimal k-core, stop, otherwise:
Dissect
as follows:
Find the maximum k-core that is an induced subgraph of
call it
(
[link] ).
For each vertex
go to step 1, using for the new
and induced subgraph of
such that
This process finds all k-cores in the original
To sketch a proof:
An algorithm that finds all induced subgraphs in
and then filters k-cores from the rest will trivially enumerate all induced k-cores in
The k-core enumeration algorithm described is equivalent to such an algorithm. By in turn eliminating every vertex from a graph, the algorithm find all induced subgraphs except for those it skips. The skipped subgraphs will never generate k-cores not already generated:
Skipped subgraphs have at least one vertex of degree less than
with respect to that subgraph; call this vertex set
The subgraph may contain vertices that would have degrees less than
if excluding the vertices in
call this set
There may also be vertices dependent on the vertices in
and
to maintain a degree of
; call those
We can continue forming these sets until
is a k-core for some positive integer
Define
as
Trivially, take some induced subgraph of
called
Consequently, no induced subgraph of
will contain a k-core including any vertices in
since no vertex in
has gained degree upon finding an induced subgraph, and, consequently, the collective
still cannot meet the degree threshold to be included in a k-core.
Subgraphs are skipped iff they contain vertices in