

| << Chapter < Page | Chapter >> Page > |
Blocking is another kind of memory reference optimization. As with loop interchange, the challenge is to retrieve as much data as possible with as few cache misses as possible. We’d like to rearrange the loop nest so that it works on data in little neighborhoods, rather than striding through memory like a man on stilts. Given the following vector sum, how can we rearrange the loop?
DO I=1,N
DO J=1,NA(J,I) = A(J,I) + B(I,J)
ENDDOENDDO
This loop involves two vectors. One is referenced with unit stride, the other with a stride of N. We can interchange the loops, but one way or another we still have
N -strided array references on either
A or
B , either of which is undesirable. The trick is to
block references so that you grab a few elements of
A , and then a few of
B , and then a few of
A , and so on — in neighborhoods. We make this happen by combining inner and outer loop unrolling:
DO I=1,N,2
DO J=1,N,2A(J,I) = A(J,I) + B(I,J)
A(J+1,I) = A(J+1,I) + B(I,J+1)A(J,I+1) = A(J,I+1) + B(I+1,J)
A(J+1,I+1) = A(J+1,I+1) + B(I+1,J+1)ENDDO
ENDDO
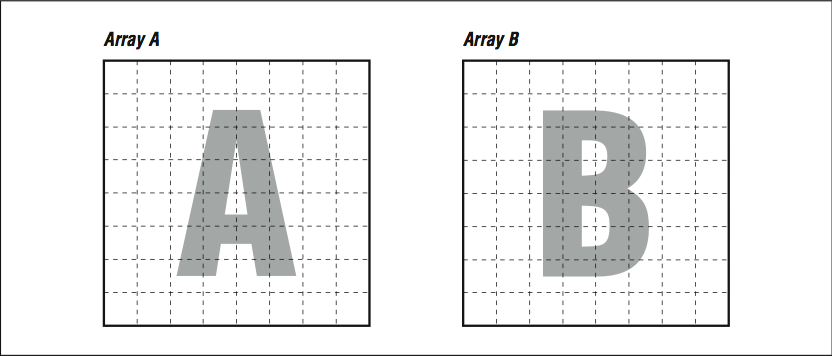
Use your imagination so we can show why this helps. Usually, when we think of a two-dimensional array, we think of a rectangle or a square (see [link] ). Remember, to make programming easier, the compiler provides the illusion that two-dimensional arrays A and B are rectangular plots of memory as in [link] . Actually, memory is sequential storage. In FORTRAN, a two-dimensional array is constructed in memory by logically lining memory “strips” up against each other, like the pickets of a cedar fence. (It’s the other way around in C: rows are stacked on top of one another.) Array storage starts at the upper left, proceeds down to the bottom, and then starts over at the top of the next column. Stepping through the array with unit stride traces out the shape of a backwards “N,” repeated over and over, moving to the right.
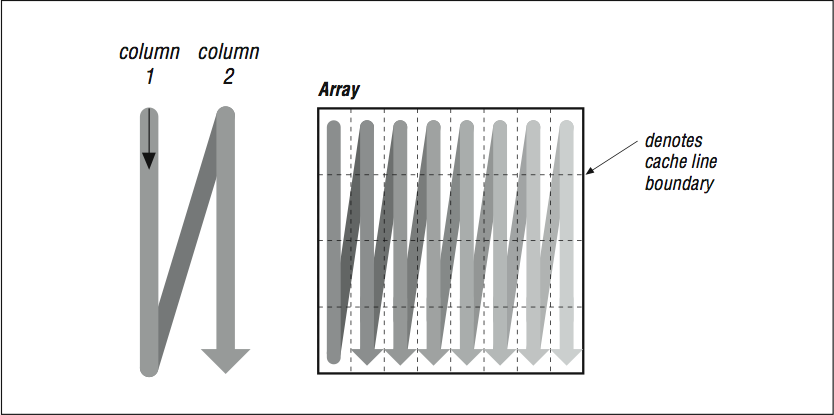
Imagine that the thin horizontal lines of
[link] cut memory storage into pieces the size of individual cache entries. Picture how the loop will traverse them. Because of their index expressions, references to
A go from top to bottom (in the backwards “N” shape), consuming every bit of each cache line, but references to
B dash off to the right, using one piece of each cache entry and discarding the rest (see
[link] , top). This low usage of cache entries will result in a high number of cache misses.
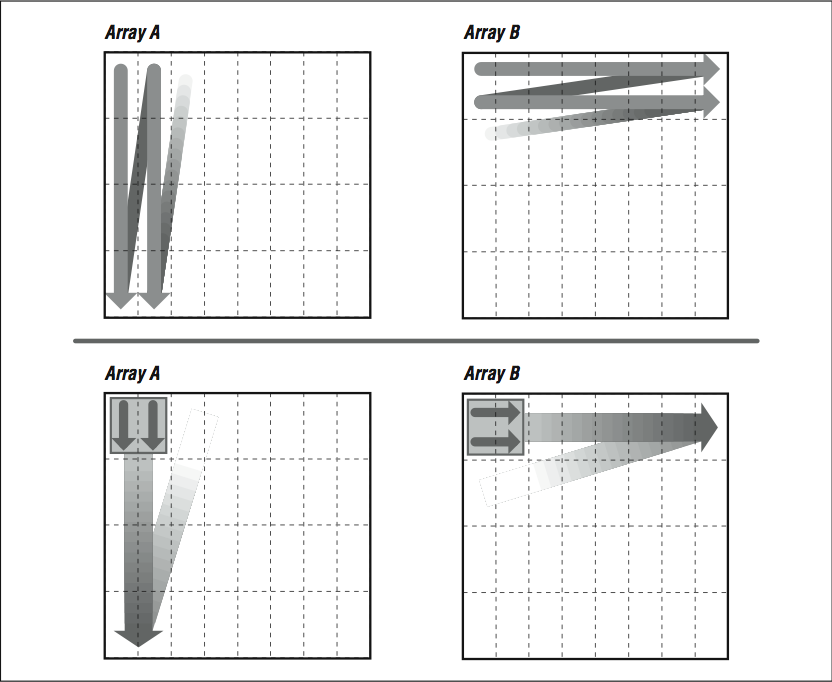
If we could somehow rearrange the loop so that it consumed the arrays in small rectangles, rather than strips, we could conserve some of the cache entries that are being discarded. This is exactly what we accomplished by unrolling both the inner and outer loops, as in the following example. Array
A is referenced in several strips side by side, from top to bottom, while
B is referenced in several strips side by side, from left to right (see
[link] , bottom). This improves cache performance and lowers runtime.
For really big problems, more than cache entries are at stake. On virtual memory machines, memory references have to be translated through a
TLB . If you are dealing with large arrays,
TLB misses, in addition to cache misses, are going to add to your runtime.
Here’s something that may surprise you. In the code below, we rewrite this loop yet again, this time blocking references at two different levels: in
2×2 squares to save cache entries, and by cutting the original loop in two parts to save
TLB entries:
DO I=1,N,2
DO J=1,N/2,2A(J,I) = A(J,I) + B(I,J)
A(J+1,I) = A(J+1,I) + B(I+1,J)A(J,I+1) = A(J,I+1) + B(I+1,J)
A(J+1,I+1) = A(J+1,I+1) + B(I+1,J+1)ENDDO
ENDDODO I=1,N,2
DO J=N/2+1,N,2A(J,I) = A(J,I) + B(I,J)
A(J+1,I) = A(J+1,I) + B(I+1,J)A(J,I+1) = A(J,I+1) + B(I+1,J)
A(J+1,I+1) = A(J+1,I+1) + B(I+1,J+1)ENDDO
ENDDO
You might guess that adding more loops would be the wrong thing to do. But if you work with a reasonably large value of
N , say 512, you will see a significant increase in performance. This is because the two arrays
A and
B are each 256 KB × 8 bytes = 2 MB when
N is equal to 512 — larger than can be handled by the TLBs and caches of most processors.
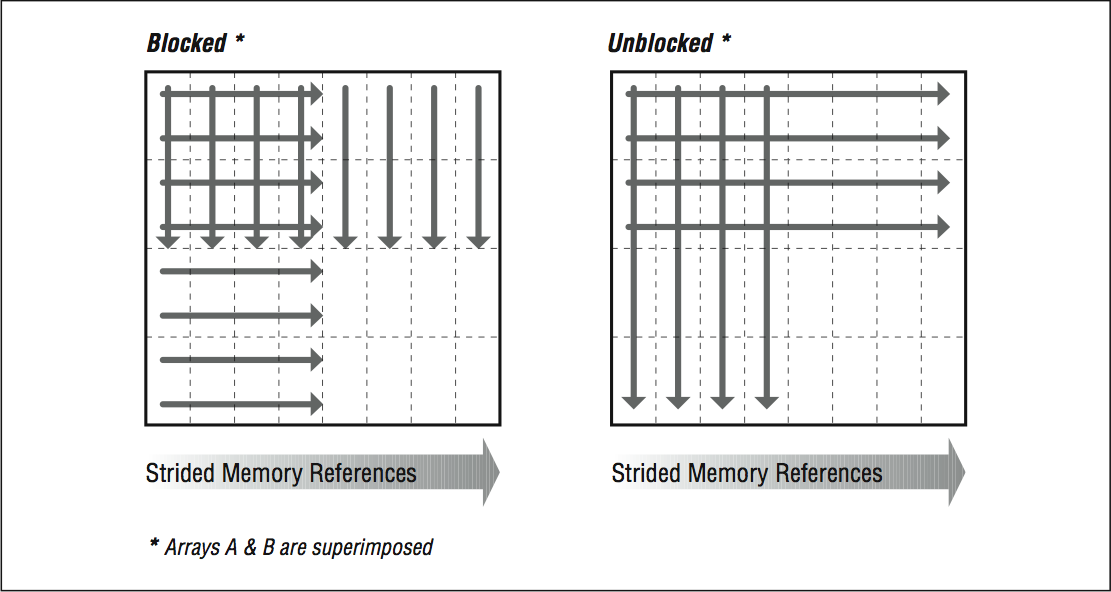
The two boxes in [link] illustrate how the first few references to A and B look superimposed upon one another in the blocked and unblocked cases. Unblocked references to B zing off through memory, eating through cache and TLB entries. Blocked references are more sparing with the memory system.
Picture of unblocked versus blocked references
You can take blocking even further for larger problems. This code shows another method that limits the size of the inner loop and visits it repeatedly:
II = MOD (N,16)
JJ = MOD (N,4)DO I=1,NDO J=1,JJ
A(J,I) = A(J,I) + B(J,I)ENDDO
ENDDODO I=1,IIDO J=JJ+1,N
A(J,I) = A(J,I) + B(J,I)A(J,I) = A(J,I) + 1.0D0
ENDDOENDDODO I=II+1,N,16
DO J=JJ+1,N,4DO K=I,I+15
A(J,K) = A(J,K) + B(K,J)A(J+1,K) = A(J+1,K) + B(K,J+1)
A(J+2,K) = A(J+2,K) + B(K,J+2)A(J+3,K) = A(J+3,K) + B(K,J+3)
ENDDOENDDO
ENDDO
Where the inner
I loop used to execute
N iterations at a time, the new
K loop executes only 16 iterations. This divides and conquers a large memory address space by cutting it into little pieces.
While these blocking techniques begin to have diminishing returns on single-processor systems, on large multiprocessor systems with nonuniform memory access (NUMA), there can be significant benefit in carefully arranging memory accesses to maximize reuse of both cache lines and main memory pages.
Again, the combined unrolling and blocking techniques we just showed you are for loops with mixed stride expressions. They work very well for loop nests like the one we have been looking at. However, if all array references are strided the same way, you will want to try loop unrolling or loop interchange first.
Notification Switch
Would you like to follow the 'High performance computing' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|