

| << Chapter < Page | Chapter >> Page > |
The Holy Grail for early RISC machines was to achieve one instruction per clock. The idealized RISC computer running at, say, 50 MHz, would be able to issue 50 million instructions per second assuming perfect pipeline scheduling. As we have seen, a single instruction will take five or more clock ticks to get through the instruction pipeline, but if the pipeline can be kept full, the aggregate rate will, in fact, approach one instruction per clock. Once the basic pipelined RISC processor designs became successful, competition ensued to determine which company could build the best RISC processor.
Second-generation RISC designers used three basic methods to develop competitive RISC processors:
The way you get two or more instructions per clock is by starting several operations side by side, possibly in separate pipelines. In [link] , if you have an integer addition and a multiplication to perform, it should be possible to begin them simultaneously, provided they are independent of each other (as long as the multiplication does not need the output of the addition as one of its operands or vice versa). You could also execute multiple fixed-point instructions — compares, integer additions, etc. — at the same time, provided that they, too, are independent. Another term used to describe superscalar processors is multiple instruction issue processors.
Decomposing a serial stream
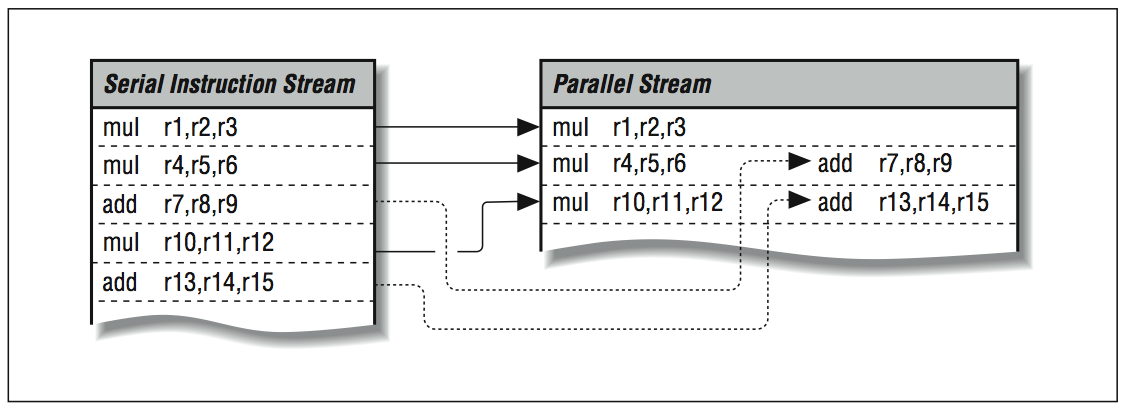
The number and variety of operations that can be run in parallel depends on both the program and the processor. The program has to have enough usable parallelism so that there are multiple things to do, and the processor has to have an appropriate assortment of functional units and the ability to keep them busy. The idea is conceptually simple, but it can be a challenge for both hardware designers and compiler writers. Every opportunity to do several things in parallel exposes the danger of violating some precedence (i.e., performing computations in the wrong order).
Roughly stated, simpler circuitry can run at higher clock speeds. Put yourself in the role of a CPU designer again. Looking at the instruction pipeline of your processor, you might decide that the reason you can’t get more speed out of it is that some of the stages are too complicated or have too much going on, and they are placing limits on how fast the whole pipeline can go. Because the stages are clocked in unison, the slowest of them forms a weak link in the chain.
If you divide the complicated stages into less complicated portions, you can increase the overall speed of the pipeline. This is called superpipelining . More instruction pipeline stages with less complexity per stage will do the same work as a pipelined processor, but with higher throughput due to increased clock speed. [link] shows an eight-stage pipeline used in the MIPS R4000 processor.
Mips r4000 instruction pipeline
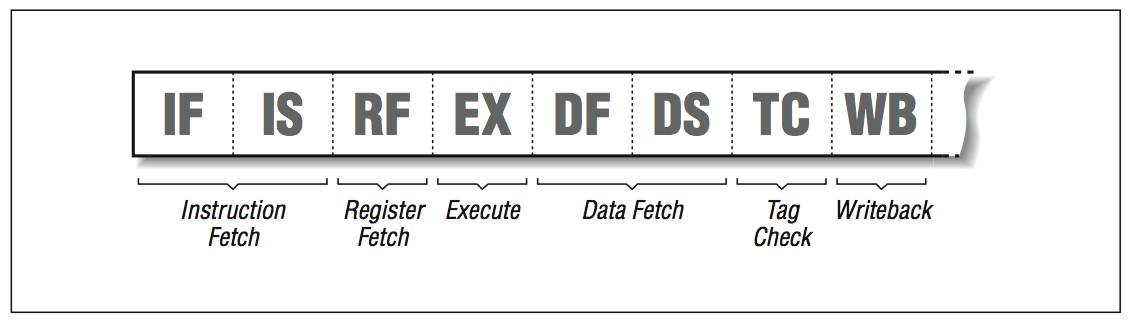
Theoretically, if the reduced complexity allows the processor to clock faster, you can achieve nearly the same performance as superscalar processors, yet without instruction mix preferences. For illustration, picture a superscalar processor with two units — fixed- and floating-point — executing a program that is composed solely of fixed-point calculations; the floating-point unit goes unused. This reduces the superscalar performance by one half compared to its theoretical maximum. A superpipelined processor, on the other hand, will be perfectly happy to handle an unbalanced instruction mix at full speed.
Superpipelines are not new; deep pipelines have been employed in the past, notably on the CDC 6600. The label is a marketing creation to draw contrast to superscalar processing, and other forms of efficient, high-speed computing.
Superpipelining can be combined with other approaches. You could have a superscalar machine with deep pipelines (DEC AXP and MIPS R-8000 are examples). In fact, you should probably expect that faster pipelines with more stages will become so commonplace that nobody will remember to call them superpipelines after a while.
Notification Switch
Would you like to follow the 'High performance computing' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|

|
|
|
|
|

|
|

|