

| << Chapter < Page | Chapter >> Page > |
Consider the filter in [link] with transfer function
We can rewrite it as
which represents the convolution . This operation can be represented in matrix form [link] as follows,

System [link] can be viewed as [link] ,
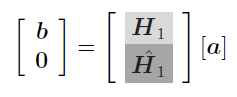
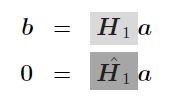
If , equations [link] and [link] describe the same square systems as equations [link] and [link] , letting in the former systems to become in the latter ones. Therefore when the number of impulse response samples to be matched is equal to , solving [link] for the coefficients and is equivalent to applying Pade's method to matching the first values of the impulse response . In consequence, this method is known as Pade's method for IIR filter design [link] or simply Pade approximation method [link] , [link] . Pade's method is an interpolation algorithm; since the number of samples to be interpolated must be equal to the number of filter parameters, Pade's method is limited to very large filters, which makes it impractical.
The relationship of the above method with Prony's method can be seen by posing Prony's method in the -domain. Consider the function from [link] ,
The -transform of is given by
where denotes the -transform operator. By linearity of the -transform [link] ,
Using
(the left equality is true since for by assumption) in [link] we get
The numerator and denominator in [link] are two polynomials in of degrees and respectively. Expanding both polynomials, equation [link] becomes
Assuming does not affect the formulation of . This is equivalent to dividing both the numerator and denominator of [link] by . From [link] it is clear that Prony's method is in fact a particular case of the Pade approximation method described earlier in this section (with ). From [link] and [link] we have
Therefore, given samples of one can solve for the parameters and in [link] merely by applying partial fraction expansion [link] on [link] .
Consider the systems in [link] and [link] . If then [link] is an overdetermined system and cannot be solved exactly in general. However, it is possible to find a least squares approximation following an approach similar to the one used in the frequency domain design method from [link] . Given samples of an impulse response , we rewrite as
where
Following the same formulation of [link] , the filter coefficients and are found by solving for and in
where is an matrix given by
The error analysis for these algorithms is equivalent to the one performed in [link] . In fact, both approaches (frequency sampling versus Pade's method) are quite similar. Among the common properties, both methods use an equation error criterion rather than the more useful solution error. However, it is worth to point out that in the time domain (Pade) approach, samples of the impulse response are used to make the approximation, and the method uses a linear convolution rather than the cyclic one from the frequency domain approach. Also, since the latter method uses a uniform sampling grid within the complete frequency spectrum between and instead of using the first few samples of an infinitely long sequence ( ), the approximation properties of the frequency domain method are superior.
Notification Switch
Would you like to follow the 'Iterative design of l_p digital filters' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|