

| << Chapter < Page | Chapter >> Page > |
The basic idea is to select based on the training data themselves. Let , , ...be a sequence of model spaces of increasing sizes/complexities with
Let
be a function from that minimizes the empirical risk. This gives us a sequence of selected models Also associate with each set a value that measures the complexity or “size” of the set . Typically, is monotonically increasing with (since the sets are of increasing complexity) and decreasing with (since we become more confident with more training data). More precisely, suppose thatthe chosen so that
for some small . Then we may conclude that with very high probability (at least ) the empirical risk is within of uniformly on the class . This type of bound suffices to bound the estimation error (variance)of the model selection process of the form , and SRM selects the final model by minimizing this bound over all functions in . The selected model is given by , where
A typical example could be the use of VC dimension to characterize the complexity of the collectionof model spaces i.e., is derived from a bound on the estimation error.
Consider a very large class of candidate models . To each assign a complexity value . Assume that the complexity value is chosen so that
This probability bound also implies an upper bound on the estimation error and complexity regularization is based on the criterion
Complexity Regularization and SRM are very similar and equivalent in certain instances. A distinguishing feature of SRM and complexityreqularization techniques is that the complexity and structure of the model is not fixed prior to examining the data; the data aid in theselection of the best complexity. In fact, the key difference compared to the Method of Sieves is that these techniques can allow the data toplay an integral role in deciding where and how to average the data.
Probability bounds of the forms in [link] and [link] are the foundation for SRM and complexity regularization techniques.The simplest of these bounds are known as PAC bounds in the machine learning community.
In order to develop complexity regularization schemes we will need to revisit the estimation error / approximation error trade-off. Let for some space of models .
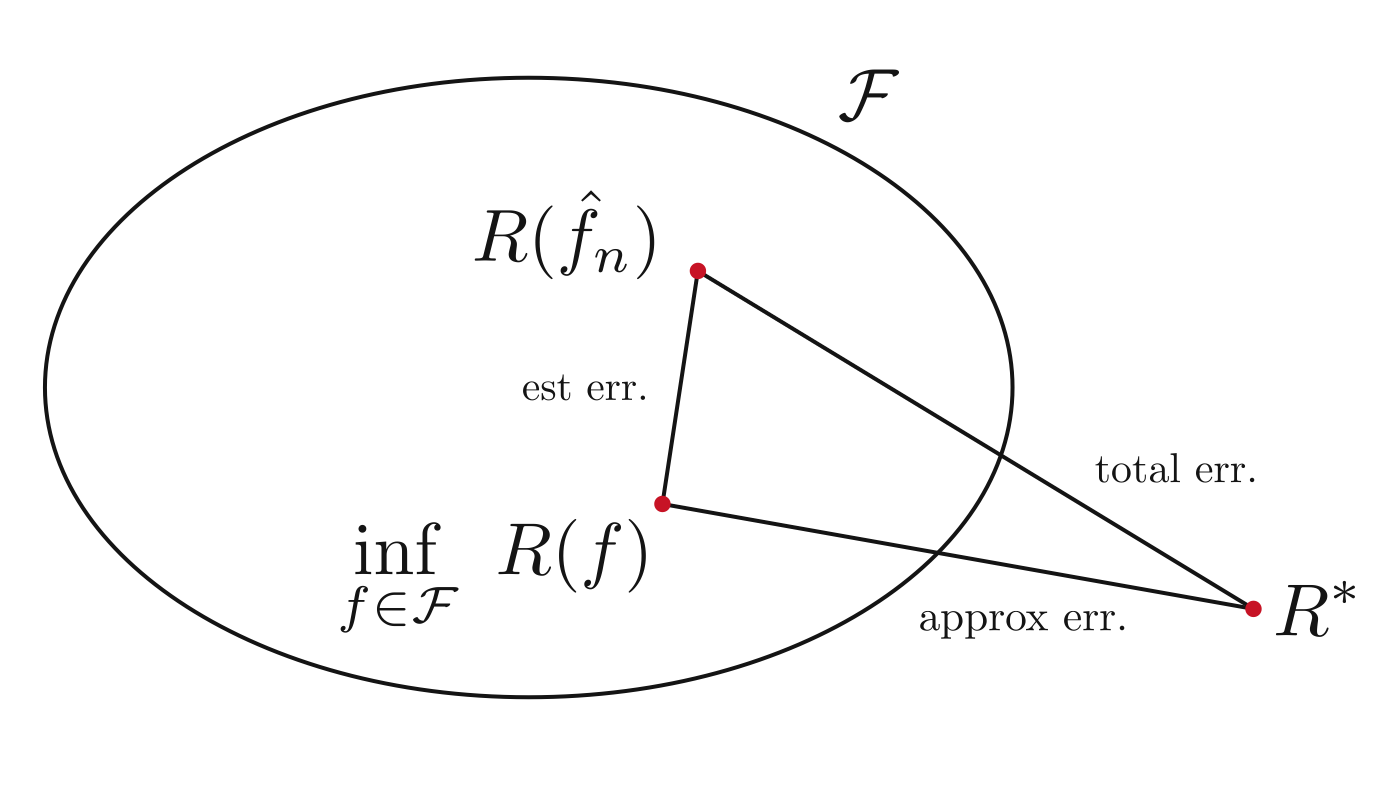
The approximation error depends on how close is close to , and without making assumptions, this is unknown. The estimation error isquantifiable, and depends on the complexity or size of . The error decomposition is illustrated in [link] . The estimation error quantifies how much we can “trust” the empiricalrisk minimization process to select a model close to the best in a given class.
Probability bounds of the forms in [link] and [link] guarantee that the empirical risk is uniformly close to the true risk, and using [link] and [link] it is possible to show that with high probability the selected model satisfies
or
The estimation error will be small if is close to . PAC learning expresses this as follows. We want to be a “probably approximately correct” (PAC) model from . Formally, we say that is accurate with confidence , or PAC for short, if
This says that the difference between and is greater than with probability less than . Sometimes, especially in the machine learning community, PAC bounds are stated as, “with probability of at least , ”
To introduce PAC bounds, let us consider a simple case. Let consist of a finite number of models, and let denote that number. Furthermore, assume that .
= set of all histogram classifiers with M bins .
Assume and , where . Let , where . Then for every and ,
Since , it follows that . In fact, there may be several such that . Let .
The last inequality follows from the fact that if , then the probability that i.i.d. samples will satisfy is less than or equal to . Note that this is simply the probability that . Finally apply the inequality to obtain the desired result.
Note that for sufficiently large, is arbitrarily small. To achieve a -PAC bound for a desired and we require at least training examples.
CorollaryAssume that and . Then for every
Recall that for any non-negative random variable with finite mean, . This follows from an application of integration by parts.
Minimizing with respect to produces the smallest upper bound with
Notification Switch
Would you like to follow the 'Statistical learning theory' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|

|
|
|
|
|

|
|

|