The algorithm described above runs in approximately exponential
time, which is to be expected since it solves an NP-hard problem.
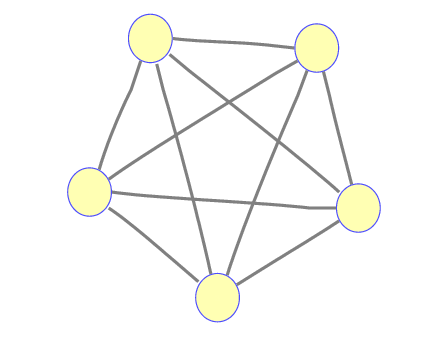
A clique for which
The enumeration of k-cores reduces to the NP complete clique problem
[link] as follows:
A clique is a k-core for which the number of vertices in the core is equal to
(
[link] ).
The clique problem is: determine whether an arbitrary graph contains a clique of at least size
If we could accomplish k-core enumeration in polynomial time, say
where
is the number of nodes in the graph, then:
We could find cores of all
in, at most,
time, because there is no
core in a given graph for which
exceeds
Without increasing fundamental run-time, we could flag each of those k-cores which is a clique. In doing so, we find all cliques.
By simply finding the largest of this group of cliques, we have solved the clique problem in polynomial time.
Consequently, k-core enumeration belongs to the class of NP-hard problems, meaning that it is not clear whether an algorithm that runs significantly faster than exponential time can be devised.
That is not to say, however, that the algorithm cannot be improved upon at all. For instance, one of our implementations takes advantage of the fact that, if we form an induced subgraph
by removing some vertex
from a graph
if
is not in a k-core, then the graph
resulting from removing any of
's neighbors that are not in a k-core from
will have the same maximum k-core as
Also, our algorithm takes care not to revisit previously enumerated branches. Different approaches can certainly speed up an algorithm to solve the problem, but it is not clear that any approach will make the algorithm run in sub-exponential time.
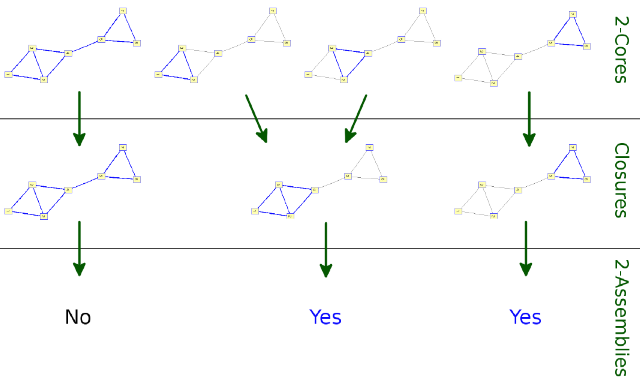
Assembly enumeration
k-Assembly enumeration on a reduced set of k-cores.
Upon enumerating all k-cores, every unique closure of a k-core is analyzed to determine whether any one of the k-cores that closes to that closure is tight (
[link] ). Checking tightness involves nothing more clever than simply verifying the above definition of tight. If at least one of the cores that closes to a given closure is tight, then that closure is a collected into the set of k-assemblies, otherwise, it is ignored.
Experimentation
After devising an algorithm to find every k-assembly, we attempted to discover attributes about k-assemblies through, first, generating random graphs, and then, enumerating the assemblies contained in those graphs.
Random graph generation
We employed two primary types of random graphs.
A Bernoulli random graphA scale-free Cooper-Frieze random graph
Pick some probability
and a number of vertices,
Create a graph
for which
For all pairs of vertices,
where
and
an edge
with probability
The scale-free Cooper-Frieze random graph (
[link] )
[link] . As we implement it:
pick some positive integer
;
;
which are 1-indexed lists.
where
and
where
and
Begin with a graph
where
and
(That is, G is a graph with a single vertex which has a single edge connected to itself).
Do the "Old" procedure with probability
otherwise, do the procedure "New."
Do the procedure "Add Edges."
Old:
with probability
choose the vertex
from among the set of vertices in
randomly, giving each vertex an even chance. Otherwise, choose
with the probability for each vertex proportional to the the degree of that vertex with respect to G.
with probability
set the boolean variable
to
Otherwise, set the variable to
choose an index of
so that the index
has a probability
of being chosen. Set the integer variable
to this chosen index.
New:
Add a new vertex
to
Call that vertex
With probability
set the boolean variable
to
Otherwise, set the variable to
choose an index of
so that the index
has a probability
of being chosen. Set the integer variable
to this chosen index.
Add Edges:
Create the set
by choosing
vertices from
The vertices are chosen randomly, either with uniform probability if
is
or in proportion to degree otherwise.