

| << Chapter < Page | Chapter >> Page > |
Our sample instruction pipeline had five stages: instruction fetch, instruction decode, operand fetch, execution, and writeback. We want this pipeline to be able to process five instructions in various stages without stalling. Decomposing each operation into five identifiable parts, each of which is roughly the same amount of time, is challenging enough for a RISC computer. For a designer working with a CISC instruction set, it’s especially difficult because CISC instructions come in varying lengths. A simple “return from subroutine” instruction might be one byte long, for instance, whereas it would take a longer instruction to say “add register four to memory location 2005 and leave the result in register five.” The number of bytes to be fetched must be known by the fetch stage of the pipeline as shown in [link] .
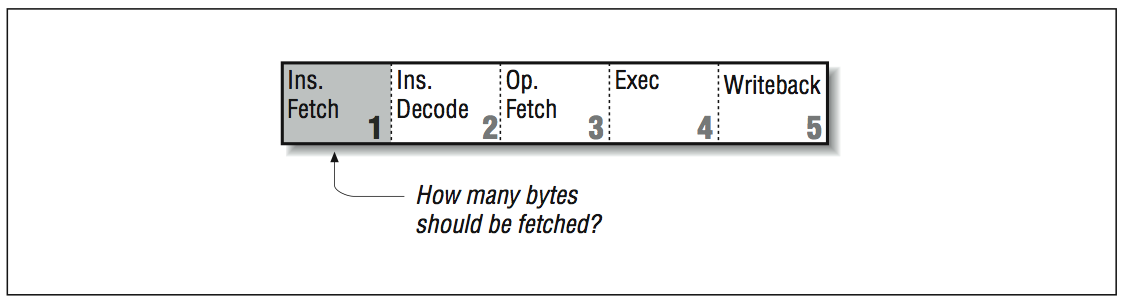
The processor has no way of knowing how long an instruction will be until it reaches the decode stage and determines what it is. If it turns out to be a long instruction, the processor may have to go back to memory and get the portion left behind; this stalls the pipeline. We could eliminate the problem by requiring that all instructions be the same length, and that there be a limited number of instruction formats as shown in [link] . This way, every instruction entering the pipeline is known a priori to be complete — not needing another memory access. It would also be easier for the processor to locate the instruction fields that specify registers or constants. Altogether because RISC can assume a fixed instruction length, the pipeline flows much more smoothly.
Variable-length cisc versus fixed-length risc instructions
![This figure is comprised of two diagrams. The diagram on the left, labeled CISC shows two boxes with the same height but variable widths. The first box, which is longer than the second, is labeled R1 arrow pointing to the left, [addr(A) + 4 * R2] + 1. The second is labeled return. Below the boxes are two arrows showing widths, labeled variable length. The second diagram is labeled RISC, and shows five connected boxes of equal size. The first reads R3, arrow pointing to the left, 4 * R2. The second reads R3, arrow pointing to the left, addr (A) + R3. The third reads R5, arrow pointing to the left, [R4]. The fourth reads R1, arrow pointing to the left, R5 + 1. The fifth is labeled return. Below the boxes is a set of arrows showing the length of all five boxes to be fixed.](/ocw/mirror/col11136_1.5_complete/m33673/graphics4.png)
As described earlier, branches are a significant problem in a pipelined architecture. Rather than take a penalty for cleaning out the pipeline after a misguessed branch, many RISC designs require an instruction after the branch. This instruction, in what is called the branch delay slot , is executed no matter what way the branch goes. An instruction in this position should be useful, or at least harmless, whichever way the branch proceeds. That is, you expect the processor to execute the instruction following the branch in either case, and plan for it. In a pinch, a no-op can be used. A slight variation would be to give the processor the ability to annul (or squash) the instruction appearing in the branch delay slot if it turns out that it shouldn’t have been issued after all:
ADD R1,R2,R1 add r1 to r2 and store in r1
SUB R3,R1,R3 subtract r1 from r3, store in r3BRA SOMEWHERE branch somewhere else
LABEL1 ZERO R3 instruction in branch delay slot...
While branch delay slots appeared to be a very clever solution to eliminating pipeline stalls associated with branch operations, as processors moved toward exe- cuting two and four instructions simultaneously, another approach was needed. Interestingly, while the delay slot is no longer critical in processors that execute four instructions simultaneously, there is not yet a strong reason to remove the feature. Removing the delay slot would be nonupwards-compatible, breaking many existing codes. To some degree, the branch delay slot has become “baggage” on those “new” 10-year-old architectures that must continue to support it.
Notification Switch
Would you like to follow the 'High performance computing' conversation and receive update notifications?

|
|
|
|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|