

| << Chapter < Page | Chapter >> Page > |
The popular POSIX (Portable Operating System Interface) Thread API provides a multi-platform interface for creating multi-threaded applications on a variety of UNIX platforms. Multi-threaded applications split the processing load across multiple cores in a computer. Most modern computers (including our test machine) contain CPUs with 2,4, or 8 individual cores, all of which can process data concurrently. Applications can be easily made parallel when significant portions of the data being operated on are independent of any other portion of data.
We recognized that p-threads presented a significant opportunity to improve the efficiency of our filter construction because each channel's data stream is completely independent of any other channel's data. Therefore, we sought to split the processing load for all the channels to multiple threads, all of which can run concurrently.
The first p-thread implementation is very similar to previous single-threaded implementations. The parameters and data structures are exactly the same as before. The filter coefficients were held constant for all channels (for speed). The primary difference here is that each thread is responsible for filtering a portion of the channels. For example, with 256 channels and 4 p-threads, use the following equal division of processing load:
The code was designed to handle arbitrary numbers of p-threads with the pre-condition that the number of threads evenly divides the number of channels. We did our test runs using the standard configuration (256 channels, 600,000 data points, 100 cycles) with 1, 2, 4, 8, 16 and 32 p-threads. A control run with all operations performed on the main thread was also executed. Results for all runs are shown in Table 1.
| Number of Threads | Runtime (s) |
| Control (main thread) | 48.075 |
| 1 | 64.302 |
| 2 | 96.755 |
| 4 | 123.931 |
| 8 | 67.629 |
| 16 | 141.329 |
| 32 | 121.134 |
The results we obtained from implementation results appear promising, but note that all runs were slower than the fastest single-threaded implementation. We decided to apply the intrinsic operations from the SSE3 instruction set that we developed in the previous section to the p-thread applications. Note that for SSE3 to work with p-threads, the pre-condition for the number of p-threads is modified. SSE3 only operates on batches of 4 floats at a time, so the number of channels that each thread operates on must be divisible by 4. In essence:
With the same standard run configuration, this pre-condition still supported test runs with 1, 2, 4, 8, 16 and 32 p-threads, along with a control run with execution on the main thread. The results of all runs are shown in Table 2.
| Number of Threads | Runtime (s) |
| Control (main thread) | 48.333 |
| 1 | 50.109 |
| 2 | 88.632 |
| 4 | 138.090 |
| 8 | 62.481 |
| 16 | 103.901 |
| 32 | 78.219 |
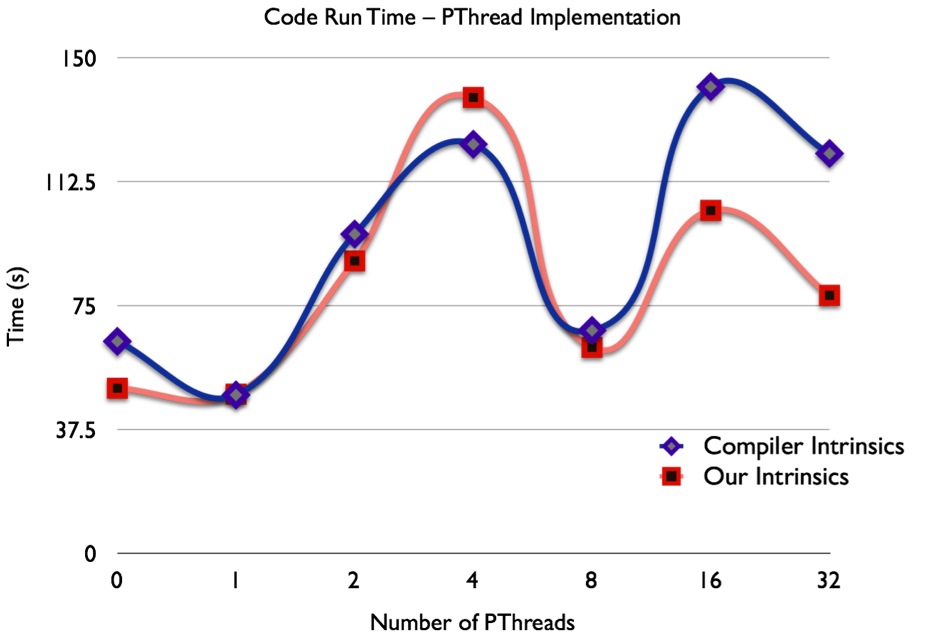
Note from the figure that the p-thread speed takes much longer for low (between 1 and 4) and high (greater than 8) numbers of p-threads. Marginally decent performance occurs with 8 p-threads on our benchmark computer, which yielded a result of 67.6 seconds using compiler optimizations, and 62.5 seconds using our SSE3 code. Note that the run time for the single-threaded implementation runs at around 48 seconds.
The behavior here definitely does not seem intuitive. With higher processor utilization, the multi-threaded runs take longer than their single-threaded counterparts. After some thought, we concluded that three events were occurring:
Taking these issues into accounts, we focused our efforts into reorganizing the data structures used by the filter bank.
Notification Switch
Would you like to follow the 'Efficient real-time filter design for recording multichannel neural activity' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|
|
|
|

|
|

|
|
|
|
|

|